本文介绍如何使用 ARIMA 预测 COVID-19 趋势。数据来源为 CSSEGISandData/COVID-19。
选择参数
传统的做法是利用差分观察数据是否稳定来确定 d,利用 自相关图 ACF 和 偏自相关图 PACF 分别确定 q,p 的值。下面尝试一种用网格搜索法来确定参数的思路。
对于每日新增确诊病例数,大致确定 (p, d, q),以及 seasonal-(P, D, Q) 的范围,时序周期为 7 天,通过迭代不同参数的组合来获取最佳参数。在评估和比较不同参数的模型时,使用 AIC 值来评估,AIC 的值越小,则模型越优。
| |
| |
检验模型
通过“网格搜索”找到了最佳拟合模型的参数,使用最佳参数值建立一个新的 ARIMA 模型。
| |
| |
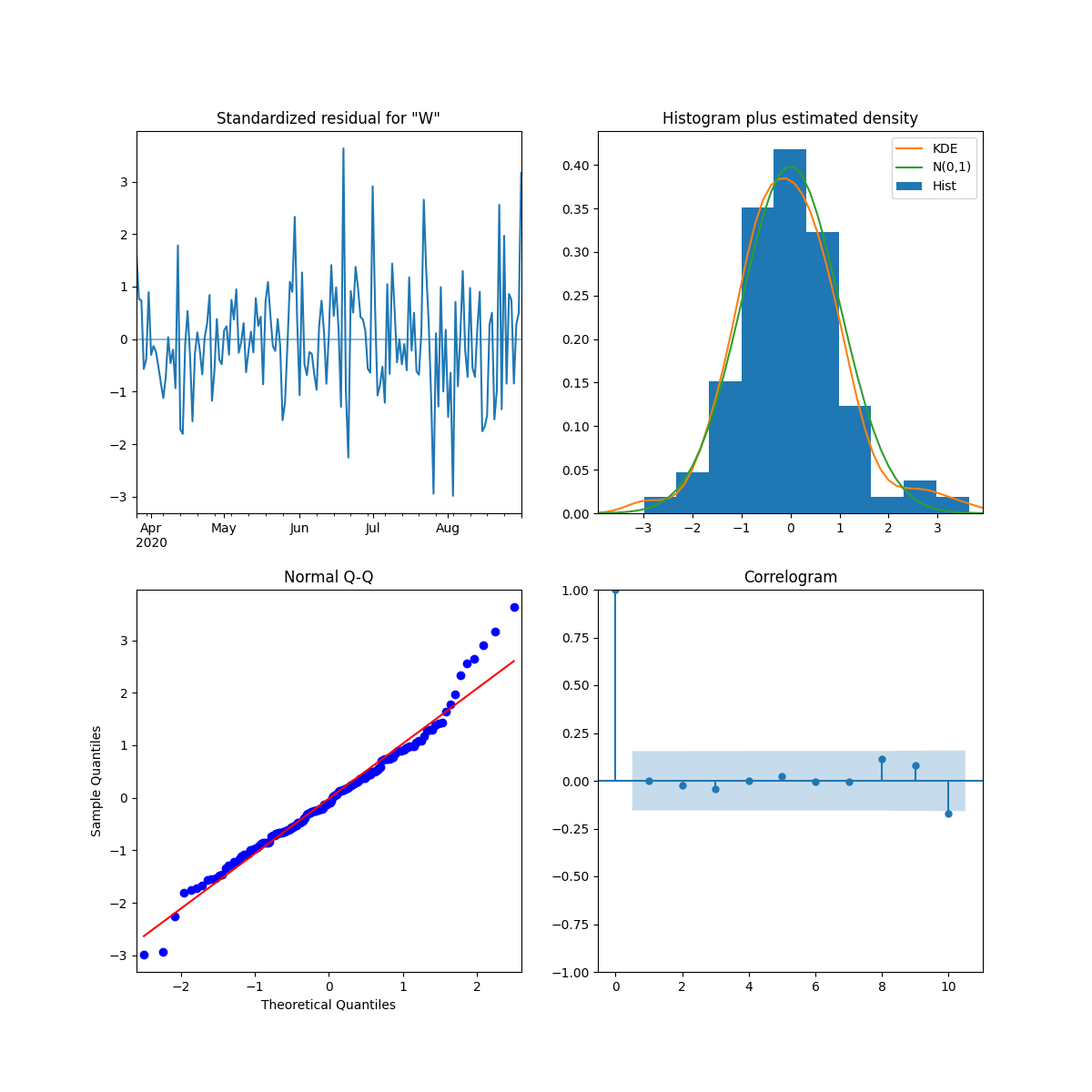 如上图:
如上图:
- 左上观察残差的均值是否接近 0;
- 右上看残差是否接近正态分布;
- 左下 Q-Q 图查看是否接近红线;
- 右下查看相关性是否在阈值之内。
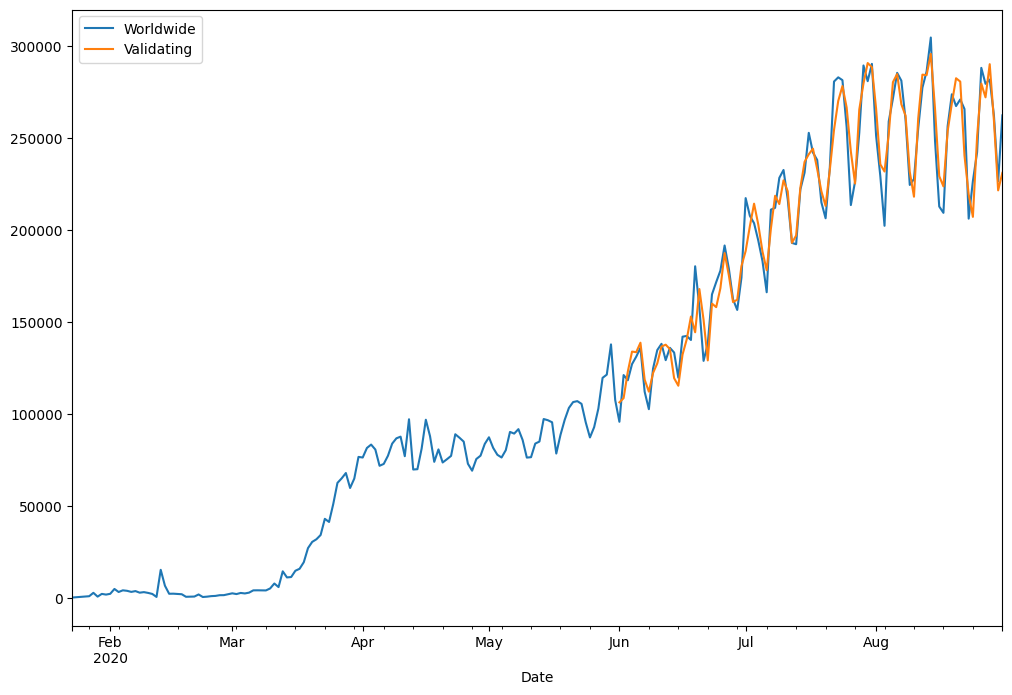 如上图,预测的红线与实际的蓝线非常接近。
如上图,预测的红线与实际的蓝线非常接近。
预测结果
| |
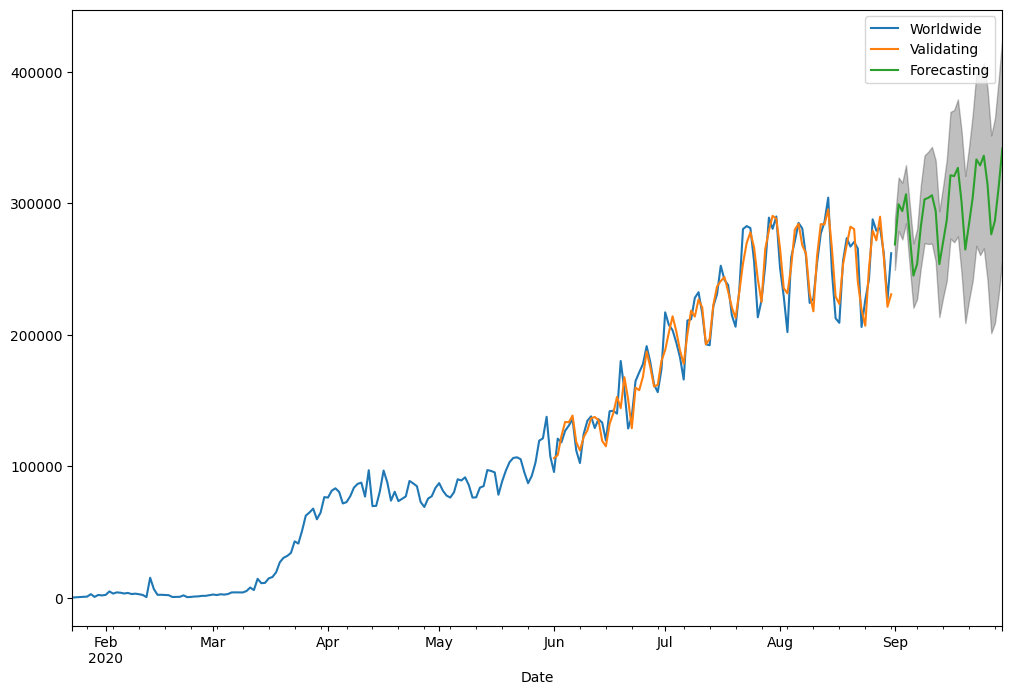 上图就是每日新增确诊病例在接下来 30 天的走势。
上图就是每日新增确诊病例在接下来 30 天的走势。
用同样的方法,调整不同的参数,还可以预测累计确诊病例下个月的走势。
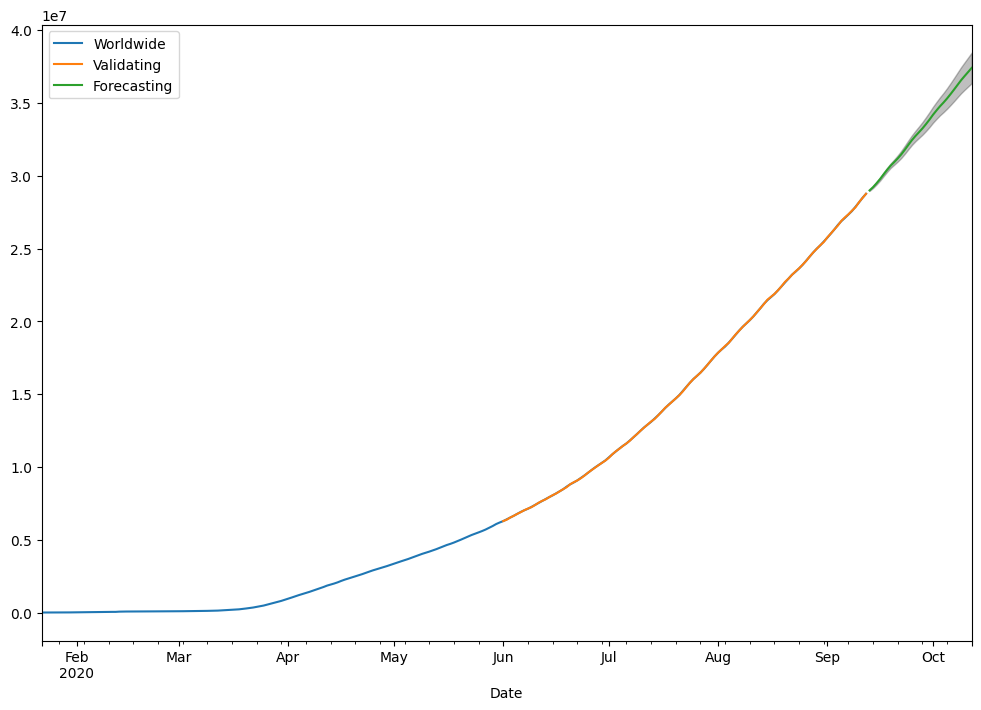 挑两天的预测值如下表,
挑两天的预测值如下表, 到时做个对比, 已更新:
| 日期 | 预测值下限 | 预测值上限 | 预测值均值 | 实际值 |
|---|---|---|---|---|
| 2020/10/01 | 33643630 | 34741650 | 34192640 | 34290251 |
| 2020/10/10 | 35913420 | 37804960 | 36859190 | 37207057 |
