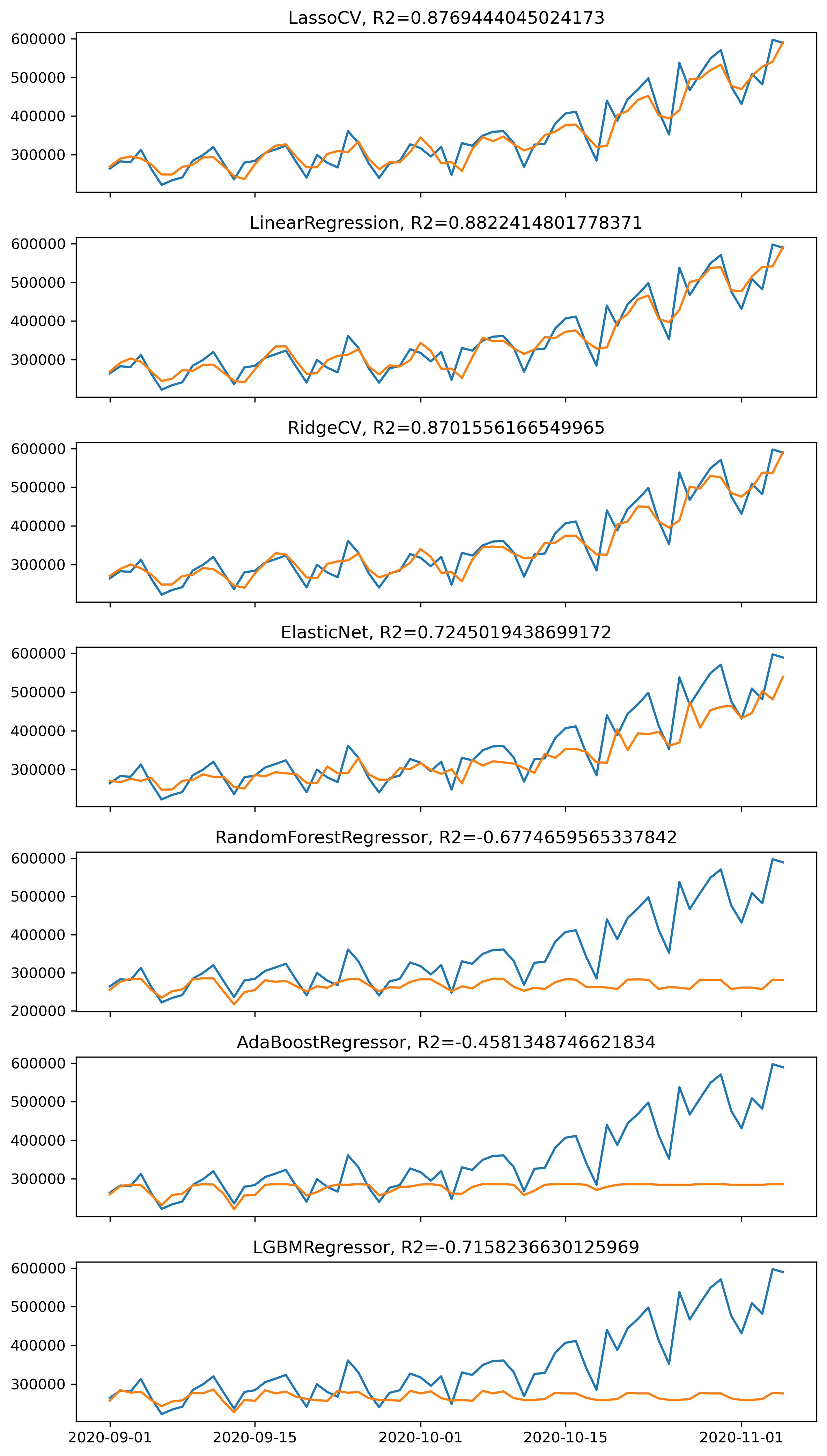
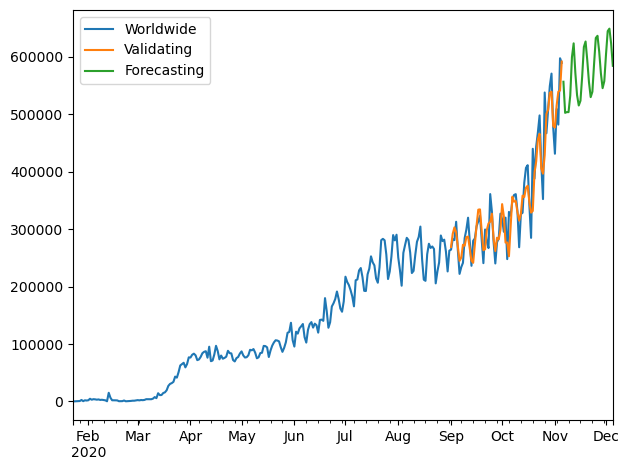
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
| def timeseries_split(X, y, test_size, pred_size):
# 将数据分割成训练集、测试集,并根据需要预测的天数准备预测集
test_index = int(len(X) * (1 - test_size))
X_train = X.iloc[:test_index]
y_train = y.iloc[:test_index]
X_test = X.iloc[test_index:len(X) - pred_size]
y_test = y.iloc[test_index:len(X) - pred_size]
X_pred = X.iloc[-pred_size:]
y_pred = y.iloc[-pred_size:]
return X_train, y_train, X_test, y_test, X_pred, y_pred
def prepare_data(data,
lag_start,
lag_end,
test_size,
target_encoding=False,
pred_days=7):
# 用来产生特征数据,其中:
# lag_start与lag_end:平移特征的范围(可调整优化),test_size:测试集占比
# target_encoding:是否要开启均值特征,pred_days:预测多少天
last_day = data.index.max()
pred_day = pd.date_range(start=last_day,
periods=pred_days + 1,
freq='1d')
pred_day = pred_day[pred_day > last_day]
future_data = pd.DataFrame({
'time': pred_day,
'y': np.zeros(len(pred_day))
})
future_data.set_index('time', drop=True, inplace=True)
data = pd.concat([data, future_data])
for i in range(lag_start, lag_end):
data['lag_{}'.format(i)] = data.y.shift(i)
data['diff_lag_{}'.format(lag_start)] = data['lag_{}'.format(
lag_start)].diff(1)
data['day'] = data.index.day
data['weekday'] = data.index.weekday
data['is_weekend'] = data.weekday.isin([5, 6]) * 1
if target_encoding:
test_index = int(len(data) * (1 - test_size))
data['weekday_avg'] = list(
map(
dict(data[:test_index].groupby('weekday')['y'].mean()).get,
data.weekday))
data.drop(['day', 'weekday', 'is_weekend'], axis=1, inplace=True)
data = data.fillna(0)
y = data.dropna().y
X = data.dropna().drop(['y'], axis=1)
X_train, y_train, X_test, y_test, X_pred, y_pred = timeseries_split(
X, y, test_size, pred_days)
return X_train, y_train, X_test, y_test, X_pred, y_pred
|